Preparing for CDC with DB2 on IBM i (AS/400)

Written by the Popsink Team
Why choose CDC for data replication?
Change Data Capture (CDC) is a methodology that identifies and captures data changes in real time, enabling seamless data replication across systems. For source systems like IBM i (AS/400) running DB2, CDC provides significant benefits by minimizing the operational impact during data extraction and stands out as the preferred method for data replication due to its efficiency and minimal impact on source systems.
Traditional data replication methods often rely on batch processing and full table scans, which can strain system resources, slow down applications, and disrupt business processes. In contrast, CDC captures only incremental changes—such as inserts, updates, and deletes—by leveraging the native journaling capabilities of DB2. This ensures:
1. Minimal Performance Impact: Since CDC reads changes directly from journals, it avoids expensive queries on source tables, keeping resource usage low.
2. Reduced System Load: By processing only the data that has changed, CDC reduces CPU and I/O consumption on the source system.
3. Non-Intrusive Operation: CDC works independently of application logic, ensuring that existing applications and workflows remain unaffected.
4. Enhanced Scalability: Even as transaction volumes grow, the incremental nature of CDC allows the source system to maintain consistent performance.
By prioritizing system stability and efficiency, CDC ensures that data can be replicated for analytics while prioritizing the performance of critical operational systems.
Setting up CDC on DB2 for IBM i
Concepts
Before we delve into how to setup CDC and other topics related to it, it's important to understand a few concepts that will appear frequently below.
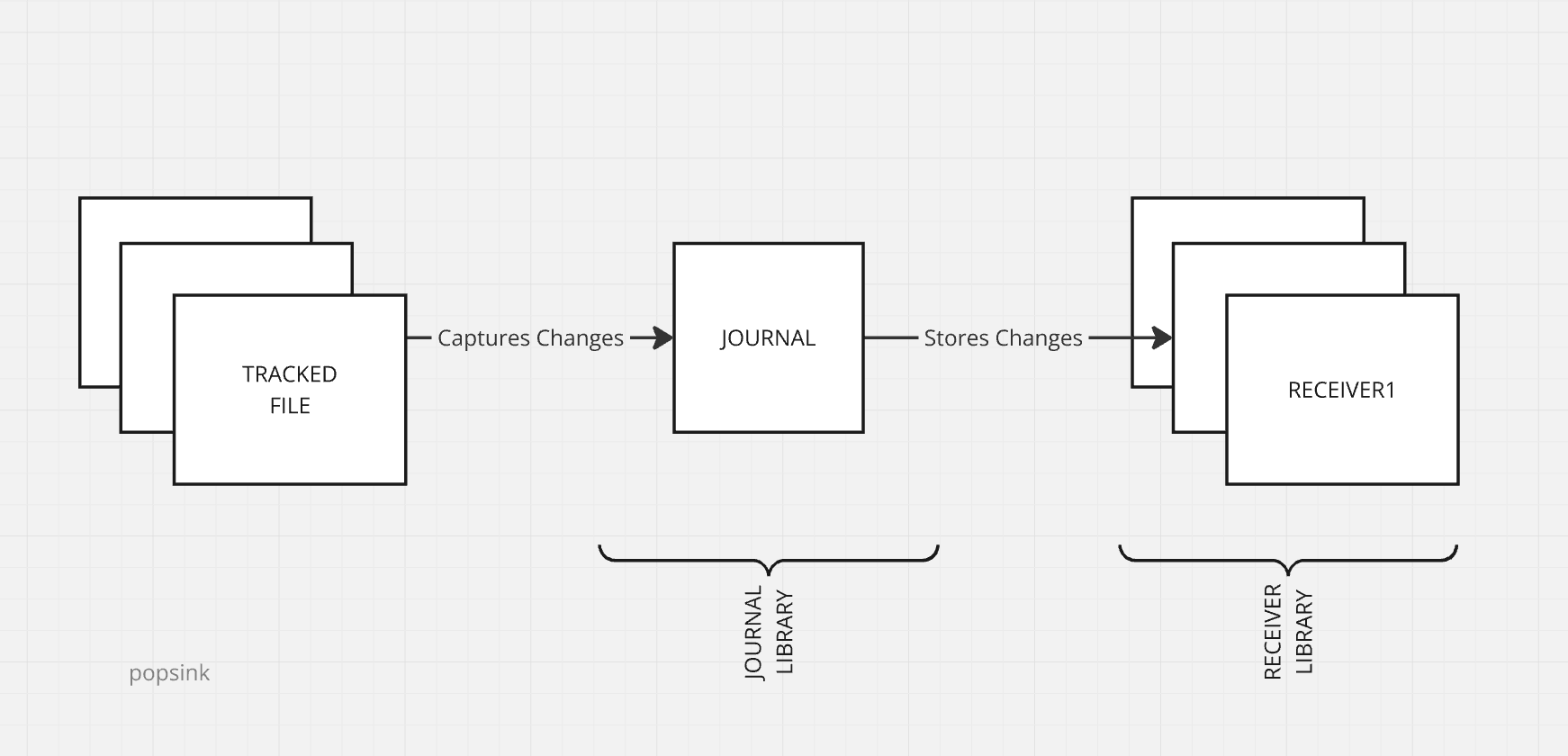
Journal Receiver <RECEIVER_NAME>
The Journal Receiver is an object that physically stores the change records. It contains the actual before-and-after images of the data, along with metadata, timestamps, and transaction information. They can be detached and archived as needed to manage storage or to transfer data out.
Journal <JOURNAL_NAME>
The Journal is a database object that acts as a tracking mechanism for recording changes made to specific database objects. Journals maintain metadata about changes and can point to one or more Journal Receivers where the detailed change records are kept.
Journal Library <JOURNAL_LIB>
The journal library is the library where the journal itself is stored. It organizes and manages the journal objects, ensuring they are accessible for tracking database changes. It serves as the repository for the journal definitions and facilitates the configuration of the journaling environment.
Journal Receiver Library <RECEIVER_LIB>
The Journal Receiver Library does the same for Journal Receivers. Journal Receivers can be stored in a separate library from Journals to allow for better organization, security, and maintenance.
Configure the Journal
CDC relies on DB2's journaling capabilities to capture data changes. To enable CDC capabilities on your AS/400 machine, follow the steps below and replace {*_NAME} with actual names.
Step 1 - Create a Journal Receiver:
CRTJRNRCV <RECEIVER_LIB>/<RECEIVER_NAME>
Step 2 - Create a Journal:
CRTJRN <JOURNAL_LIB>/<JOURNAL_NAME> <RECEIVER_LIB>/<RECEIVER_NAME>
Step 3 - Start Journaling tables/files:
STRJRNPF <FILE_LIB>/<FILE_NAME> <JOURNAL_LIB>/<JOURNAL_NAME>
Step 4 - Give relevant rights to the CDC user:
GRTOBJAUT OBJ(<JOURNAL_LIB>) OBJTYPE(*LIB) USER(popsink) AUT(*EXECUTE)
GRTOBJAUT OBJ(<JOURNAL_LIB>/*ALL) OBJTYPE(*JRNRCV) USER(popsink) AUT(*USE)
GRTOBJAUT OBJ(<JOURNAL_LIB>/<JOURNAL_NAME>) OBJTYPE(*JRN) USER(popsink) AUT(*USE *OBJEXIST)
GRTOBJAUT OBJ(<JOURNAL_LIB>/<JOURNAL_NAME>) OBJTYPE(*JRN) USER(popsink) AUT(*OBJEXIST)
GRTOBJAUT OBJ(<RECEIVER_LIB>) OBJTYPE(*LIB) USER(popsink) AUT(*EXECUTE)
GRTOBJAUT OBJ(<RECEIVER_LIB>/*ALL) OBJTYPE(*FILE) USER(popsink) AUT(*USE)Step 5 (Recommended) - Switch journaling from *AFTER to *BOTH:
By default journaling only stores the image after the change, not the one before. This can make certain operations complex, for instance Primary Key updates - these cannot be handled unless both images are available.
CHGJRNOBJ OBJ((<FILE_LIB>/<FILE_NAME> *FILE)) ATR(*IMAGES) IMAGES(*BOTH)
That's it, you've done it! You now have CDC capabilities on the tables/files that you have chosen. You can now start using a CDC solution like Popsink to safely replicate your DB2 data to any other system.
Estimating Usage and Consumption
1. Estimating Usage
Estimating the count of transactions for INSERT, UPDATE, and DELETE operations helps you anticipate your costs as CDC tools usually rely on change volumes for pricing. The query below can be run in any SQL interface to get an estimate of volumes over a 24 hours window.
SELECT
J.OBJECT,
COUNT(CASE WHEN J.JOURNAL_ENTRY_TYPE = 'PT' THEN 1 END) ASINSERT_COUNT,
COUNT(CASE WHEN J.JOURNAL_ENTRY_TYPE = 'UP' THEN 1 END) ASUPDATE_COUNT,
COUNT(CASE WHEN J.JOURNAL_ENTRY_TYPE = 'DL' THEN 1 END) ASDELETE_COUNT
FROM TABLE(QSYS2.DISPLAY_JOURNAL('<JOURNAL_LIB>', '<JOURNAL_NAME>')) AS J
WHERE J.ENTRY_TIMESTAMP >= CURRENT_TIMESTAMP - 24 HOURS
GROUP BY
J.OBJECT;
2. Estimate Disk Usage for Journaling
Journals can consume storage if they are left to accumulate, it is best to observe storage consumptions over a certain period to ensure that consumption is within acceptable range and have some level of reporting and alerting. You can ;onitor the size of journal receivers over a test period and use the DSPJRNRCVA command to analyze storage trends.
Housekeeping: Journal retention
It is important to note that logs (aka journal entries) provide resillience. They are used to replay the past efficiently and to recover from incidents like network loss or consumer downtime. It may be tempting to keep logs ad vitam eternam but that would be unwise for your machines. That's where rentention comes in. Log retention helps maintain efficient system operations by managing storage usage and ensuring only relevant data is available for auditing or troubleshooting. Removing outdated logs prevents them from accumulating, frees up space, and keeps the system organized without unnecessary overhead. Best practice will tell you to keep logs 7 days maximum and 1 days at the very least but this may vary according to you specific needs. The command below delete log receivers and the associated logs when they are older than 7 days:
DLTJRNRCV JRNRCV(<RECEIVER_LIB>/<RECEIVER_NAME>) DLTOPT(*IGNINQMSG) SELECT(*OLD) RETENTION(7)
You can also perform this operation in SQL using the following statement:
DELETEFROM <JOURNAL_LIB>.<JOURNAL_NAME>
WHERE <LOG_DATE_COLUMN> < CURRENT DATE - 7 DAYS;
You can use wildcards like RECEIVER_NAME* in order to make sure you carpture all receivers under a specific name pattern. Also, as this is a one-off command and you actually need to perform that action on a continuous basis, it is better to schedule it to run periodically. This can be done uing WRKJOBSCDE on IBM i.
Useful scripts
Here are a few random useful scripts to manage operations around CDC workflows:
1. Stop and restart CDC services
In some particular instances, you may be required to temporarily halt CDC replication. The script below lets you stop the network interface for CDC.
ENDTCPIFC INTERFACE(<CDC_SERVER_IP>)
To restart:
STRTCPIFC INTERFACE(<CDC_SERVER_IP>)
2. Remove journaling
If you need to stop journaling a table:
ENDJRNPF FILE(<FILE_LIB>/<FILE_NAME>) JRN(<JOURNAL_LIB>/<JOURNAL_NAME>)
3. Monitor journal usage
To list active journal receivers:
WRKJRNRCV <JOURNAL_LIB>/<JOURNAL_NAME>
Conclusion
Change Data Capture is an essential tool for organizations leveraging DB2 on IBM i for analytics. By enabling safe data replication with minimal impact on operational systems, CDC ensures businesses stay agile and data-driven. Setting up CDC requires careful planning — particularly around journaling and resource usage — but the result is a robust, efficient system ready to feed modern analytics pipelines. With the setup, estimation, and maintenance tips outlined above, your CDC implementation on IBM i will be well-positioned for success.
You'll find more informations about CDC on our dedicated article www.popsink.com/blog/what-is-change-data-capture
