Managing Change Data Capture (CDC) in Snowflake

Why use Change Data Capture in Snowflake?
Change Data Capture (CDC) has become a cornerstone of modern data engineering, enabling efficient, scalable, and cost-effective data pipelines. By capturing only the changes made to data instead of reloading entire datasets, CDC provides significant advantages in terms of performance and resource utilization. When paired with Snowflake, CDC becomes even more powerful due to Snowflake’s scalability, performance, and pay-per-use model.
1. Incremental: CDC eliminates the need for full data reloads by capturing data changes as they happen. This reduces compute resources and significantly improves data availability.
2. Improved availability: incremental updates mean systems remain more available. Downtime is minimized because there’s no need for large-scale batch operations and data is captured in real-time.
3. Resiliency: CDC ensures that data pipelines are resilient to failures. If ingestion fails, pipelines can restart from watermark so that only the missed changes need to be replayed, simplifying recovery and improving pipeline reliability.
4. Decreased human effort: managing data with CDC reduces manual intervention by automating changes tracking, eliminating the need for developers or analysts to reconcile data discrepancies manually, and removing the need for orchestration thanks to continuous replication.
5. Reduced cost footprint: Snowflake’s pay-per-use pricing model means that incremental updates directly translate to lower costs. By processing only what has changed, compute costs are significantly reduced.
In this article, we’ll explore how CDC works in Snowflake, and how to implement it effectively.
What does CDC look like in Snowlake?
Basics
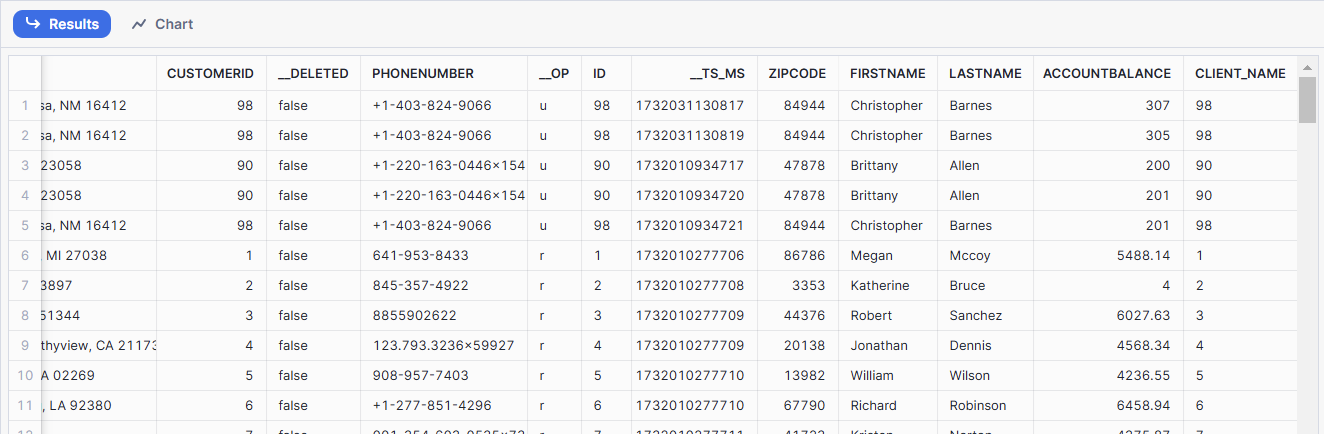
When using a CDC solution like Popsink, it will capture data changes as they happen from a source and writes it to a destination . There are 4 types of CDC operations that each reflect a certain behaviour. Those 4 types are: READ, INSERT, UPDATE, and DELETE. Here is what they stand for:
READ
As the name suggests, reads happen when past data is being read from the source. It generally happens during Initial Loads or when past data is being replayed.
INSERT
When a new row is being created in the source, it is transferred as an insert operation downstream.
UPDATE
When data changes into a source row or object, it is passed down as an update operations.
DELETE
Deleting a row or object is passed down as a delete operation. Delete operations are very important as they are otherwise not captured by other replication methods like Extract-Load and ensure consumers in Snowflake can remain compliant with GDPR and CCPA regulations.
What CDC means for Snowflake
Because CDC captures changes as it happens in a transactional way, the best way to sink the captured data in Snowflake is through Snowpipe Streaming. Snowpipe Streaming is a feature in Snowflake, it is also the most efficient way to achieve continuous data ingestion into tables, bypassing the need for batch processing. Snowpipe Streaming leverages an API to write data into Snowflake's staging area, where it is immediately committed to tables, ensuring low-latency data availability. It does not however enable merge operations, meaning that data can only be written and not updated and requires further logic to achieve a continuously up-to-date view. This is the topic of our next section.
How to manage CDC data in Snowflake?
From Change Table to State Table
As mentioned earlier, when sinking CDC data into Snowflake using Snowpipe Streaming, you will end up with an append-only table where every change is added one after the other. Snowpipe Streaming also conveniently takes care of a number of schema evolutions for you.
This is great to make the data available quickly and provides a very convenient view on historical data that can be leveraged for audits, local replays, and time travel (recreating the state of a table at a specific point in time). But what it isn't convenient for is providing an analytics-ready view on the current state of a table. Now comes the difficult part. You are going to need to build the actual state of the table by merging together the various change operations into their latest states. Snowflake offers two main approaches for implementing the state table: using MERGE statements or leveraging Dynamic Tables. Each method has its strengths and trade-offs, depending on your use case. To review both these options, we first need to get familiar with some of the labels we'll use below:
<SOURCE_CDC_TABLE>
This is the append-only table and the direct output of Snowpipe Streaming which contains the stream of change operations written one after the other as a table.
<TARGET_STATE_TABLE>
This is our current state table that contains the applied change operations and provides a mirror of the data contained in the source system as of the latest upsert operation.
<PRIMARY_KEY>
Primary key is pretty self-explanatory and refers to the dimension which you want to leverage to update rows on. It could very well be a composite key if no primary key is explicitly defined.
Option 1: Using MERGE for Change Data Capture in Snowflake
The MERGE statement is a traditional approach for upserting data into Snowflake tables. This method provides full control over how changes are applied to the target table.
MERGE INTO
<DATABASE>.<SCHEMA>.<TARGET_STATE_TABLE> ups
USING ( -- Deduplication Logic
SELECT
pop.*
FROM
<DATABASE>.<SCHEMA>.<SOURCE_CDC_TABLE> pop
WHERE
TO_TIMESTAMP_TZ(pop._TS_MS / 1000) BETWEEN
DATEADD(HOUR, -24, CURRENT_TIMESTAMP)
AND CURRENT_TIMESTAMP
QUALIFY
ROW_NUMBER() OVER (
PARTITION BY pop.<PRIMARY_KEY> ORDER BY pop.__SOURCE_TS_MS DESC
) = 1
) AS cdc
ON ups.<PRIMARY_KEY> = cdc.<PRIMARY_KEY>
AND ups.__SOURCE_TS_MS < cdc.__SOURCE_TS_MS -- Ignore out of order transactions
WHEN MATCHED AND cdc.__OP = 'd' THEN DELETE
WHEN MATCHED THEN UPDATE ALL BY NAME
WHEN NOT MATCHED AND cdc.__OP != 'd' THEN INSERT ALL BY NAME
;
Pros
Strong schema enforcement: Explicit column mapping ensures strict adherence to the target schema, making it easier to catch schema mismatches early in the process.
Customizable replay and recovery: You can manually adjust the CDC process to replay data from specific periods, making it ideal for error recovery, debugging, or re-processing historical data.
Mature and widely supported: MERGE is a standard SQL feature supported by Snowflake and other databases, making it easy to port solutions or integrate into existing workflows.
Compute-on-demand: The approach is resource-efficient, as the compute is only triggered during execution, avoiding unnecessary costs when the pipeline is idle.
Cons
Tedious schema management: at the time of writing Snowflake doesn't support dynamically mapping entire rows in the UPDATE / INSERT statement so you have to explicitly list every column, fine for small tables but a bit of a hassle for wide tables or schemas that change frequently. => EDIT: Snowflake has release MERGE ALL BY NAME which addresses this issue
Limited scalability for large schemas: managing hundreds of columns or frequent schema changes could end up requiring substantial manual effort. => EDIT: Snowflake has release MERGE ALL BY NAME which addresses this issue
Potential performance bottlenecks: as the volume of changes grows, the MERGE process can become resource-intensive due to the need to sort and match data for INSERT, UPDATE, and DELETE operations.
Option 2: Using Dynamic Tables for Change Data Capture in Snowflake
Dynamic Tables provide a modern, simplified approach to handling CDC. Snowflake automatically manages data updates based on a defined query, enabling near real-time data synchronization.
CREATE OR REPLACE DYNAMIC TABLE <DATABASE>.<SCHEMA>.<TARGET_STATE_TABLE>
LAG = '1 minute'
WAREHOUSE = <WAREHOUSE>
REFRESH_MODE = INCREMENTAL
AS
SELECT
*
FROM ( -- Only keep latest records
SELECT
pop.*
FROM
<DATABASE>.<SCHEMA>.<SOURCE_CDC_TABLE> pop
QUALIFY
ROW_NUMBER() OVER (
PARTITION BY
pop.<PRIMARY_KEY>
ORDER BY
pop.__SOURCE_TS_MS DESC
) = 1
)
WHERE
__op != 'd'
;
Pros
- Simplified setup and maintenance: Dynamic Tables eliminate the need to write complex logic for updates and inserts, automatically handling the CDC workflow based on defined queries.
- Near real-time updates: with incremental refresh and a low-latency
LAGsetting, changes are propagated quickly to the target table, enabling near real-time data availability. - Schema evolution tolerance: Dynamic Tables automatically adapt to changes in the schema of the source table, significantly reducing the effort of managing evolving datasets.
- Built-in incremental logic: Snowflake handles the deduplication and sequencing of records, removing the need to explicitly manage timestamps or row-order logic.
Cons
Potentially higher resources consumptions: Dynamic Tables require continuous compute resources for incremental refreshes, which could lead to higher costs compared to on-demand MERGE statements for infrequent updates. The always-on nature of Dynamic Tables could strain compute resources for high-throughput scenarios, especially in shared Snowflake environments.
Limited control over processing: while automated, Dynamic Tables offer less flexibility for incorporating custom business rules or handling edge cases compared to the MERGE approach, especially as INCREMENTAL is only supported for a limited number of statements.
Versioning and replay challenges: unlike manual MERGE, Dynamic Tables don’t natively support manual replays or processing data from arbitrary points in time, limiting recovery and troubleshooting options.
Conclusion
Change Data Capture in Snowflake is a powerful approach to manage incremental data updates, improving efficiency and reducing costs. The choice between MERGE statements and Dynamic Tables depends on your specific needs:
- Use MERGE if you need fine-grained control, only need to merge on a scheduled frequency, and have resources to manage schema changes.
- Use Dynamic Tables if simplicity, ease of use, and near real-time processing are your priorities.
By leveraging CDC in Snowflake, you can unlock scalable, resilient, and cost-effective data pipelines, aligning perfectly with modern data engineering principles and the needs of business critical data products.
